Premise
Now I’m selecting appropriate DB to store Shop and its Item data under those imaginary conditions.

+ Each Item belongs to 1 specific shop
+ Item info and shop info might be separately changed
+ There are 100K shops, flat file data size would be less than 100MB, sometimes updated
+ There are 1B items, flat file data size would be more than 1TB, frequently updated
+ User want to get multiple Item data by specifying IDs, together with related shop data, under similar performance of typical KVS mget
+ User want to search Item data by specifying field conditions, together with related shop data, under similar performance of typical document database search
+ I don’t want to pay money for this imaginary work (avoid using Enterprise editions)
If the data is small then I just put into Relational DataBase and utilize memory to speed up.
A: shop data
B: item data
But now I’m supposing huge data on distributed environment.
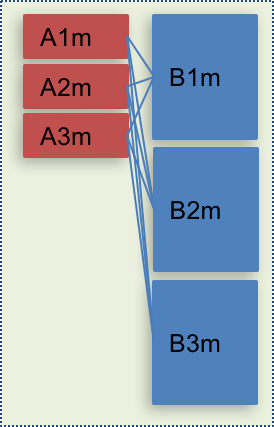
Typical case
Without any consideration, data is distributed as below and a lot of communication is needed.
1,2.3: stands for shard number
m: master
r: replica
Entire replication of small data A
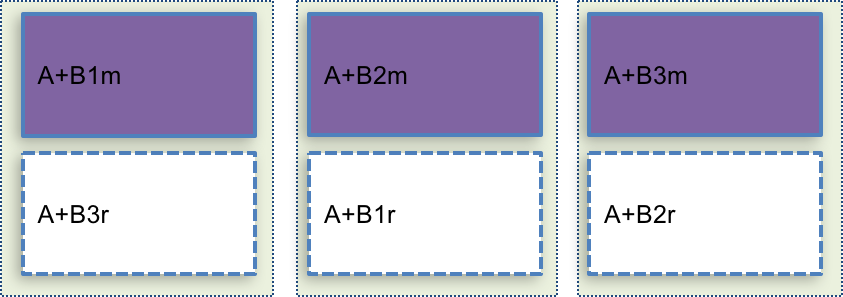
If we set number of replica == number of instance, each instance can have full set of data.
A(shop data) is small data set so we can allocate as below.
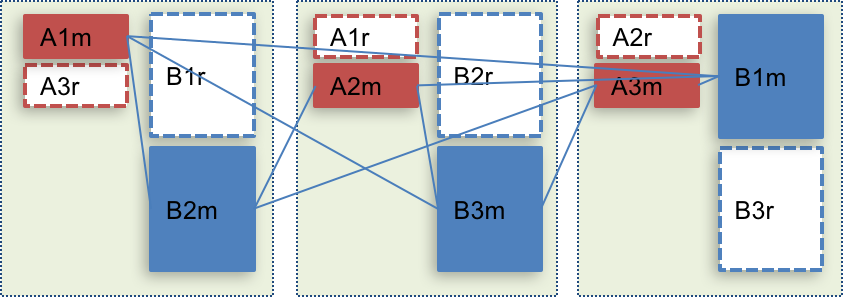
But even in this situation, we’re not sure that local communication prior to server-server communication.
It depends on each DB implementation.
So far I couldn’t find such reference in most of DB documentation.
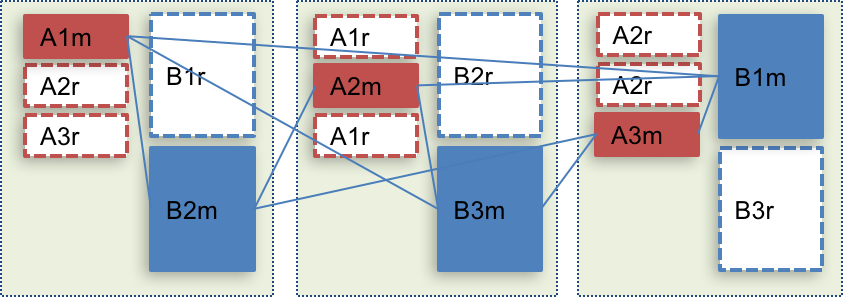
If we can force such priority, the communication will become as below.
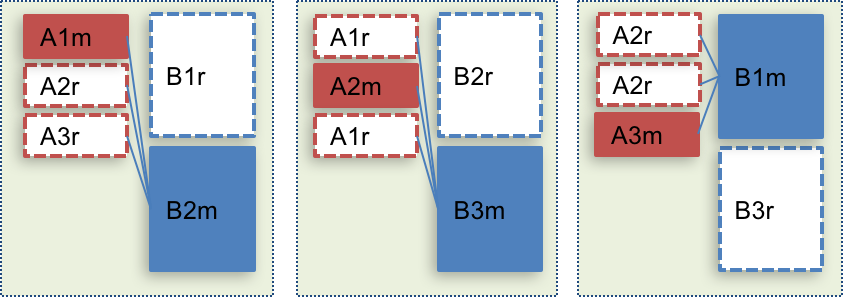
ArangoDB enterprise edition support “Satellite Collections” which clearly mentions communication as below.
(added)
VoltDB also supports that structure.
https://docs.voltdb.com/UsingVoltDB/IntroHowVoltDBWorks.php#IntroReplicate
Consistent sharding
If there is no change in the relationship between shop & item, then we can keep parent<->child structure.
And by using shop ID as hash key of both shop and item data sharding, then we can limit parent<-> child join within the same instance.
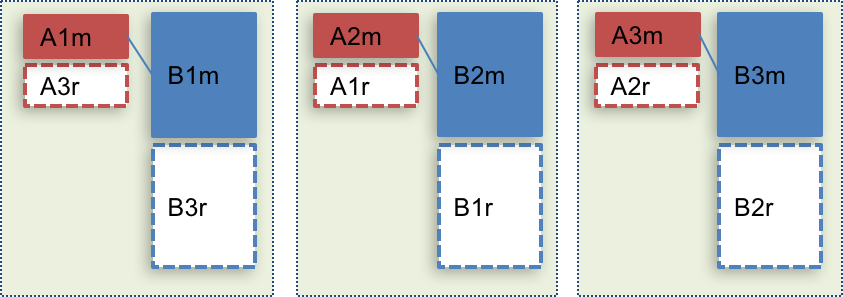
Elasticsearch and Solr supports this structure under some constraints.
https://www.elastic.co/guide/en/elasticsearch/guide/current/parent-child.html
(added)
Ignite also supports this structure.
https://apacheignite-sql.readme.io/docs/distributed-joins#collocated-joins
Denormalization
Alternatively we can denormalize the structure and put all the shop information to each item data.
When we need to update ex.) shop name, then we need to update the shop name in all the items of that particular shop.
And there is a possibility of discrepancy that the shop info update takes time and items under the same shop temporarily have different shop names.
But in return, this structure is good at read/search performance.
So if there is less update of shop and temporal discrepancy is acceptable, then it can be a good option by using fast update DBs like Couchbase.